
Standardization is crucial in order to create a true revolution in the clinical trials industry. We are getting closer to the day that all clinical trials will be accelerated by the automation of manual processes. Getting there is inevitably intertwined with analyzing clinical data in a coherent, consistent way.
How does this work?
Clinical trials are immensely diverse and examine a variety of different solutions to medical problems. Therefore, the data varies as well, and is not unified in its structure and semantic meaning. While in most cases this is no challenge for the human eye, a computer algorithm requires things to be more structured.
When data is permanent, coherent and repetitive – it means it is suited in the best way for automation. Even if the data seems identical to a human eye, minor things such as location inside the table or terminology may change the automation outcome.
In the pharmaceutical industry, where data is naturally more intricate, the task is all the more challenging. Verify by Beaconcure was able to introduce automation to the visual validation process of the statistical analysis, by automatically converting static files into machine readable format using ML based algorithms. However, we still encounter challenges and the best way to solve them is with data standardization.
When encountering a different and completely new data set, the automation will find itself somewhat clueless. Imagine the automation to be a growing child, its understanding is limited to what it has seen so far. In order for automation to optimize its analysis, the clinical data must be consistent. That means when given agreed rules for statistical analysis, the time for validation will decrease drastically.
Cross-Table Checks
In the process of statistical analysis validation, automating Cross-table checks is one of the biggest challenges the industry faces. Double programming is widely used in the industry to improve the quality of output produced in the reporting results of clinical trials. This approach is useful for individual tables, but does not compare the output across multiple tables.
Verify, an automation solution for statistical analysis outputs validation, provides cross-table validation and consistency checks quickly for all deliverables. A more detailed explanation on Verify’s solution for cross-table checks is in the link.
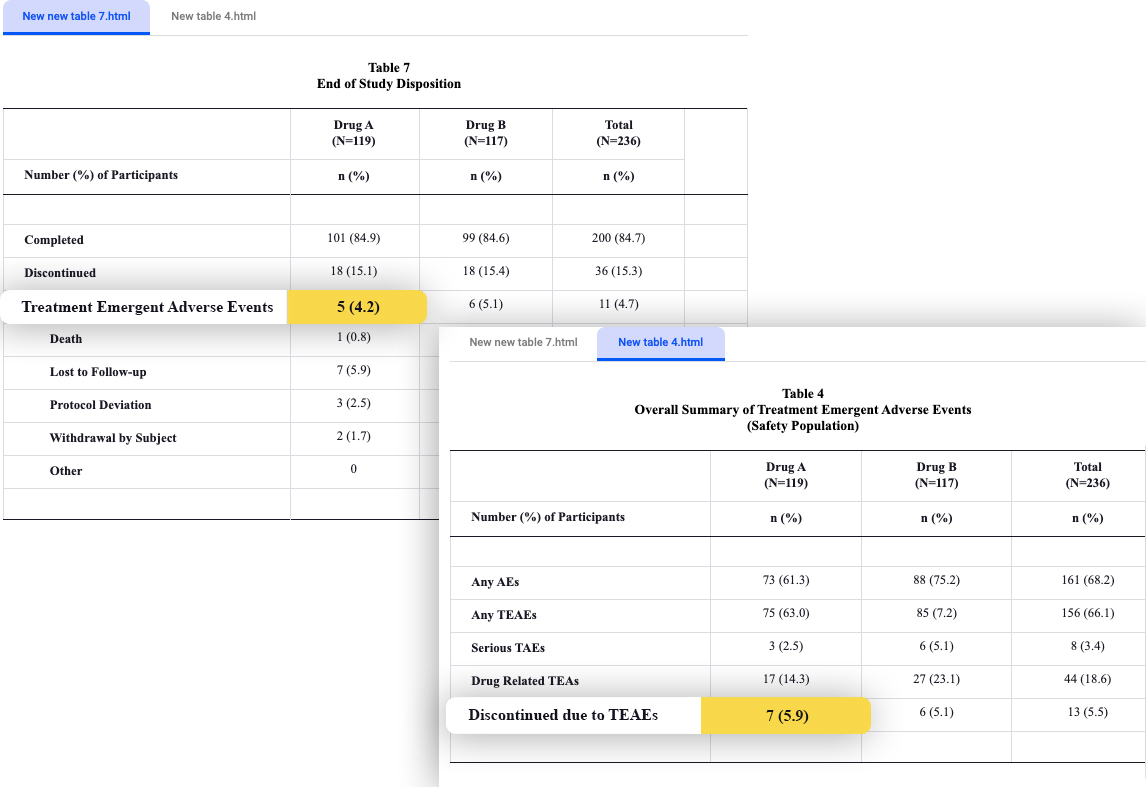
However, when talking about cross table checks, we must keep in mind that the terminology used has a key part in the way the procedure is performed. Keeping coherency in the different tables is crucial.
An interesting example is the name of the drug itself. Every drug has a name and a protocol number. We’ve observed that in clinical trials, some of the tables refer to the drug by its name, and some by its protocol number. Automation, in its most basic form, can not tell by itself if the two are the same – unless it was specifically instructed to do so (which can be done by using a reference table).
In the picture – Verify outpost demonstrating a discrepancy in a cross table check, reviewing discontinuation due to adverse events:
How Far Can This Go?
This brief explanation is a basic review of how automation can improve its actions. In reality, data standardization in the Pharma industry can lead to huge changes from the present. If the same standardization is implemented into all clinical studies , it will reduce data analysis and validation time on both ends.
Now imagine the ideal scenario, where FDA and pharmaceutical companies are using the same data analysis methodologies while going over trials – and how this can affect the time process for drugs and vaccines arriving into drugstores and hospitals, and potentially saving the lives of millions.



