Parsing is the process of analyzing a string of symbols, either in natural language, computer languages, or data structures, confronting the rules of formal grammar. Beaconcure’s take revolves around analyzing clinical data structures that appear in tables and were created with SAS programming.
Parsing is the way of the algorithm to take raw clinical tables, and put them into a formed structure. It enables the cells in the original table to be placed in their appropriate location. This is the basis for any further analysis of the data, and only after a successful parsing process, certain calculations can be applied to it.
When creating tables using SAS programming, it’s important to highlight that they can be generated in different structures and file formats. They can be done, among others, in PDF, RTF or HTML. However, each format requires a different parsing technique, and consequently have their own challenges.
If you know a little about this, you might think “there are some excellent open-source tools available out there, why not use that?”
The answer is that Beaconcure’s parser produced much more accurate results due to our expertise in clinical tables.
For example, in comparison to Amazon’s parser, which is widely used in the tech industry, there is a substantial difference in quality that the clinical trials field cannot risk.
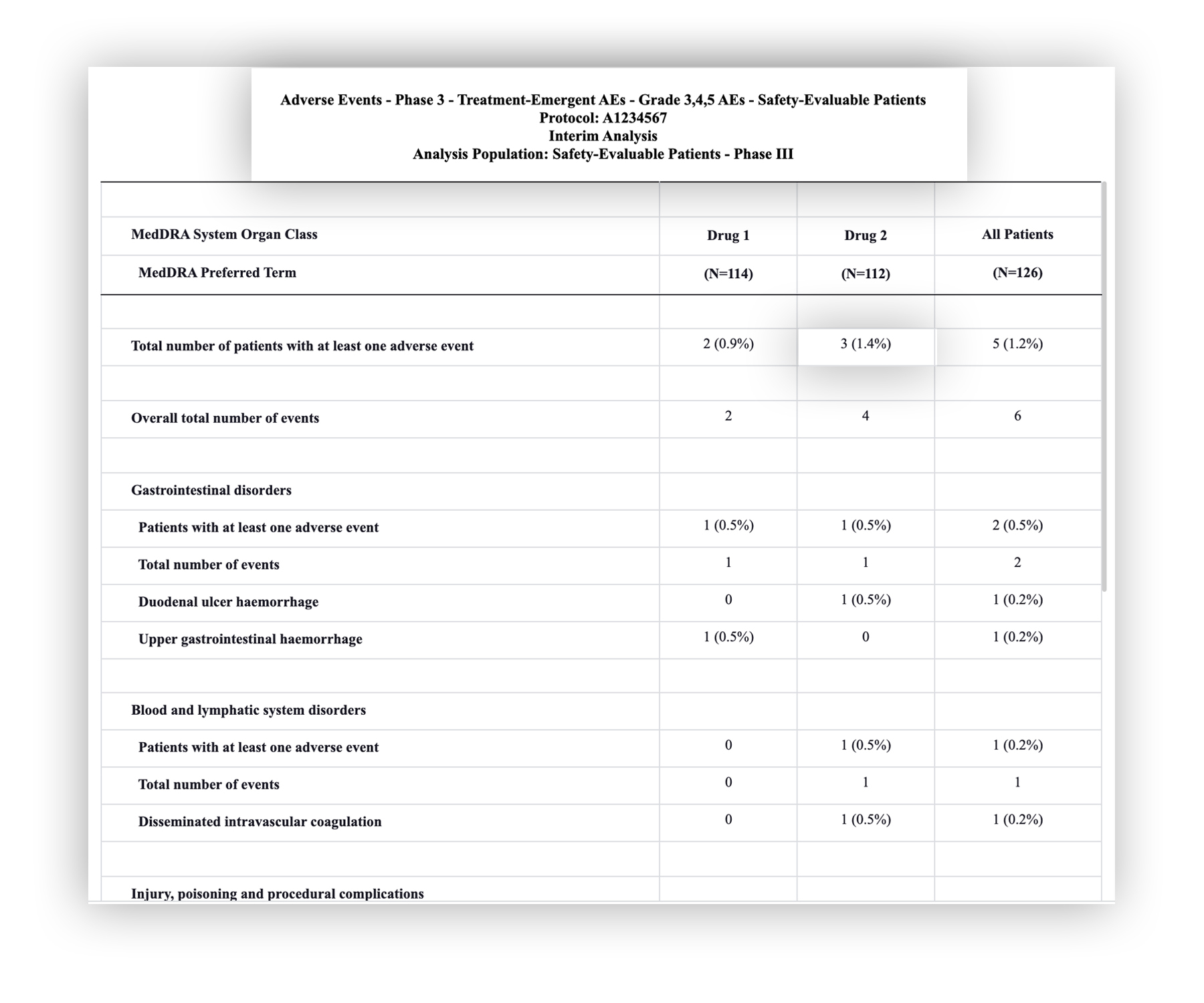
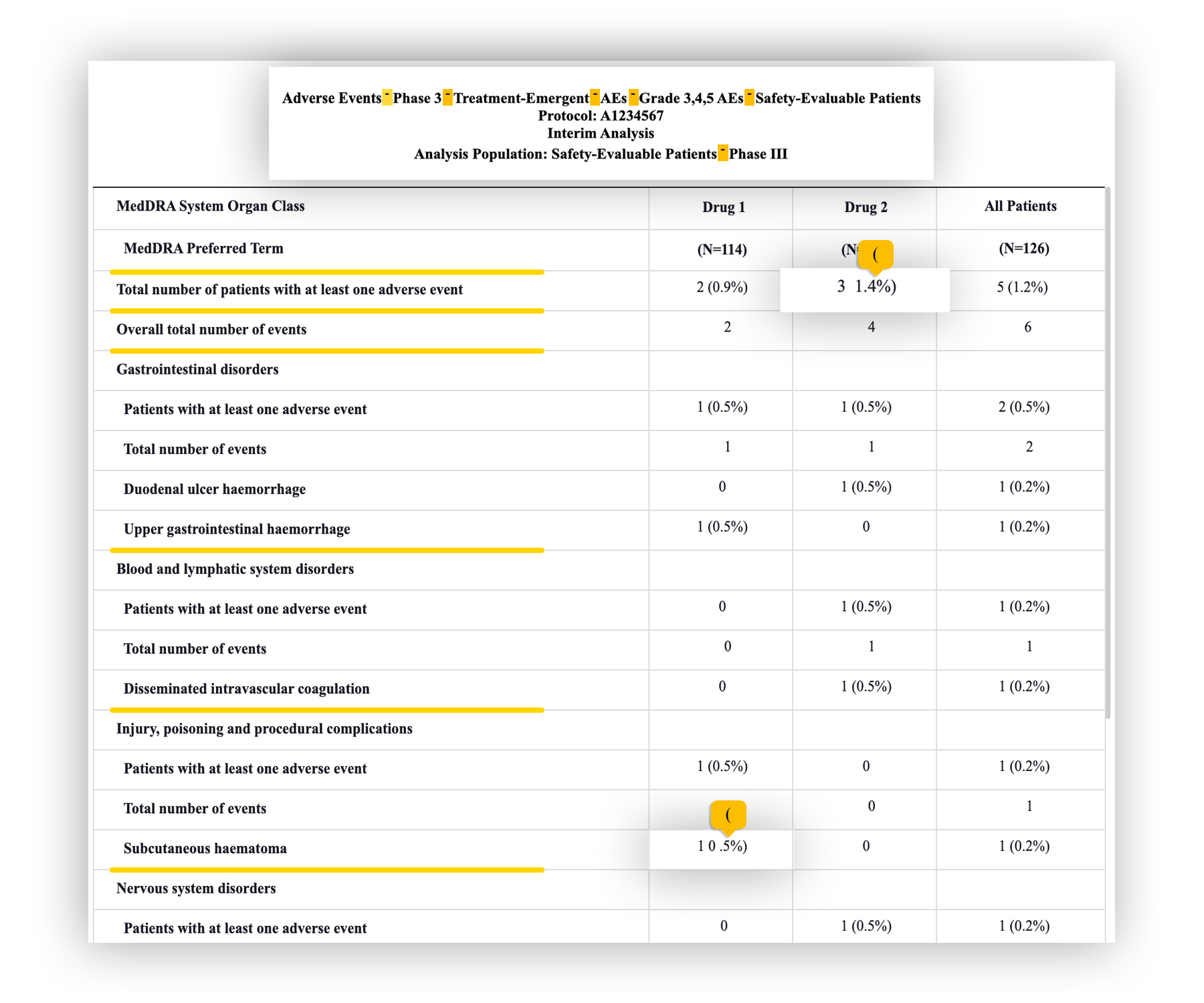
One might look at a table and see a complete structured dataset, but not all that appears clear to the human eye is necessarily easily understood by an algorithm. There are many types and forms of tables that Beaconcure analyzes, and our sophisticated parsing algorithms are equipped with handling varying structures and data, in all types of studies.
It’s important to mention that, if the original tables are not organized in a standard way, the parsing can’t reflect the data correctly. This can result in unsatisfying results for the calculations, as accurate as they may be. For that reason, maintaining a unified structure between tables is very important, so any discrepancy that might exist in the data can be located fast and efficiently.